[Laravel]-Crawler dữ liệu từ website khác
Trong dự án thực tế khi cần kiểm tra những chức năng chúng ta đều cần những nguồn data để test, việc nhập tay sẽ mất rất nhiều thời gian và dữ liệu lại không sát với thực tế. Cách khác là dùng Factory, khả quan hơn nhưng dữ liệu lại không đáp ứng được nhu cầu của bạn là về sản phẩm hoặc những bài viết trên một trang báo điện tử...
Do đó mình sẽ giới thiệu các bạn lấy dữ liệu từ một website khác, cụ thể là lấy thông tin các bài tin tức trên một website tin tức.
1, Chuẩn bị
Các bạn cài đặt sẵn một Project Laravel (Php, Composer, Mysql).
Chúng ta sẽ cài đặt package Laravel-goutte nên các bạn hãy đọc trước.
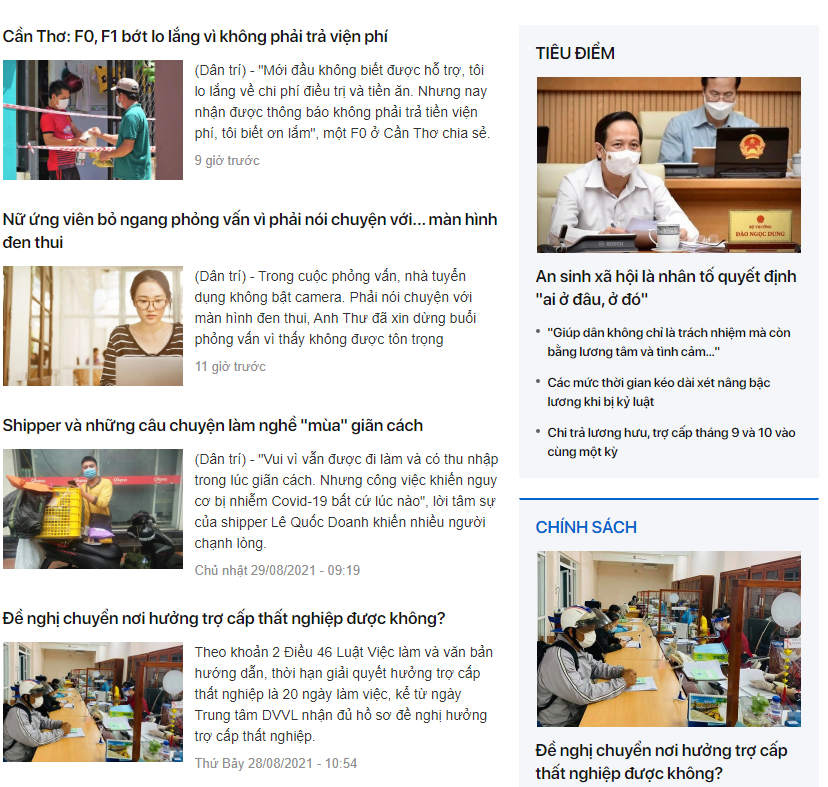
Địa chỉ website mẫu (mình sẽ cào thông tin các bài viết bên cột trái kia)
2, Cài đặt package
Đầu tiên cài đặt package bằng composer
$ composer require weidner/goutteSau đó kiểm tra xem đã cài đặt được chưa nhé
// ./composer.json
{
"require": {
"php": "^7.2",
"laravel/framework": "^8",
"weidner/goutte": "^2",
// ...
},
//...
}
Sau khi cài đặt xong các bạn khai báo trong config/app.php
// config/app.php
return [
// ...
'providers' => [
// ...
/*
* Package Service Providers...
*/
Weidner\Goutte\GoutteServiceProvider::class, // [1] This will register the Package in the laravel echo system
/*
* Application Service Providers...
*/
App\Providers\EventServiceProvider::class,
App\Providers\RouteServiceProvider::class,
],
// ...
'aliases' => [
'App' => Illuminate\Support\Facades\App::class,
'Artisan' => Illuminate\Support\Facades\Artisan::class,
// ...
'Goutte' => Weidner\Goutte\GoutteFacade::class,
// ...
],
];
Thế là đã xong phần cài đặt rồi đó, chúng ta cùng đi cào dữ liệu nào
3, Cào dữ liệu
Trong phần cào dữ liệu này mình sẽ thực hiện logic trên command line, các bạn cũng có thể sử dụng route, controller để thực hiện.
Tạo command line
$ php artisan make:command ScrapeDanTri
Bạn sẽ có thư mục \\app\Console\Commands\ScrapeDanTri.php và chúng ta sẽ thực hiện logic trong đó.
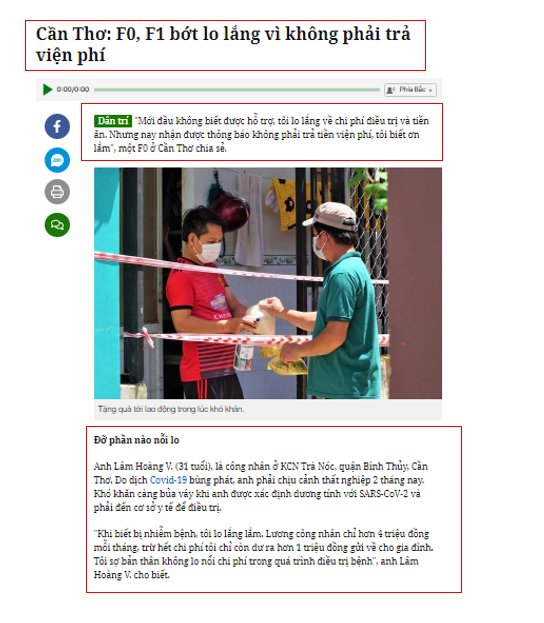
Một bài viết sẽ được chia làm 3 phần là title, description, content. Tất cả các bài ở cột bên trái mà chúng ta muốn cào sẽ có cấu trúc này. Trước tiên ta sẽ test cào phần title
Logic sẽ được xử lý trong handle(), link trong phần request GET là bài viết Cần Thơ: F0, F1 bớt lo lắng vì không phải trả viện phí bài viết đầu tiên trong list cần cào ở cột bên trái
// ScrapeDanTri.php
/**
* The name and signature of the console command.
*
* @var string
*/
protected $signature = 'scrape:dantri';
/**
* The console command description.
*
* @var string
*/
protected $description = 'Command description';
/**
* Create a new command instance.
*
* @return void
*/
public function __construct()
{
parent::__construct();
}
/**
* Execute the console command.
*
* @return int
*/
public function handle()
{
$crawler = GoutteFacade::request('GET', 'https://dantri.com.vn/lao-dong-viec-lam/can-tho-f0-f1-bot-lo-lang-vi-khong-phai-tra-vien-phi-20210829181940605.htm');
$title = $crawler->filter('h1.dt-news__title')->each(function ($node) {
return $node->text();
})[0];
print($title);
}
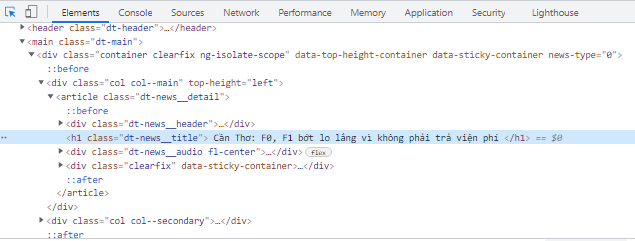
Muốn lấy được title các bạn nhấn F12 espect phần html của phần title như hình dưới đây, như các bạn thấy title là thẻ h1 và có class là dt-news__title. Vậy ta sẽ để trong filter cú pháp 'h1.dt-news__title' tương tự như DOM trong JS.
Phần protected $signature = 'command:name'; các bạn đổi tên thành 'scrape:dantri' nhé
Test thử nào, các bạn chạy command bằng temiral của Vscode nhé

Vậy mình đã lấy được title bài viết, tương tự các bạn espect lấy phần description, content và thử print ra nhé. Ở phần description nó sẽ auto lấy từ Dân Trí ở đầu dòng nên mình sẽ bỏ nó đi bằng str_replace.
//handle
$title = $crawler->filter('h1.dt-news__title')->each(function ($node) {
return $node->text();
})[0];
$description = $crawler->filter('div.dt-news__sapo h2')->each(function ($node) {
return $node->text();
})[0];
$description = str_replace('Dân trí', '', $description);
$content = $crawler->filter('div.dt-news__content')->each(function ($node) {
return $node->text();
})[0];
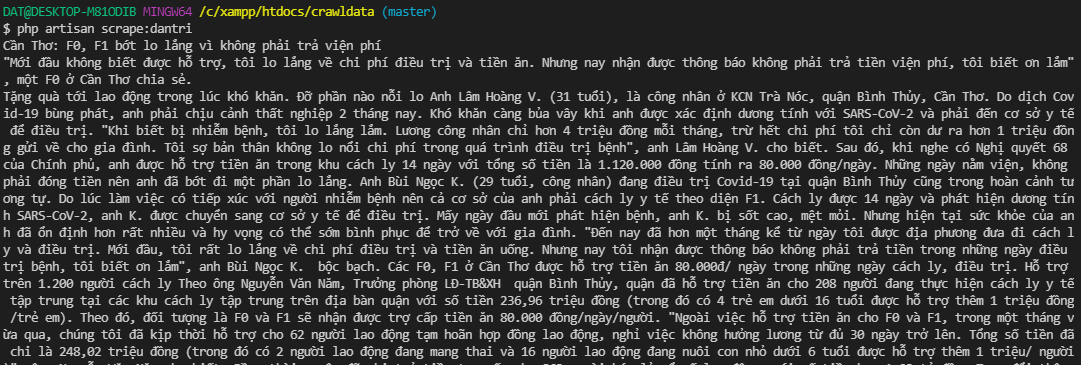
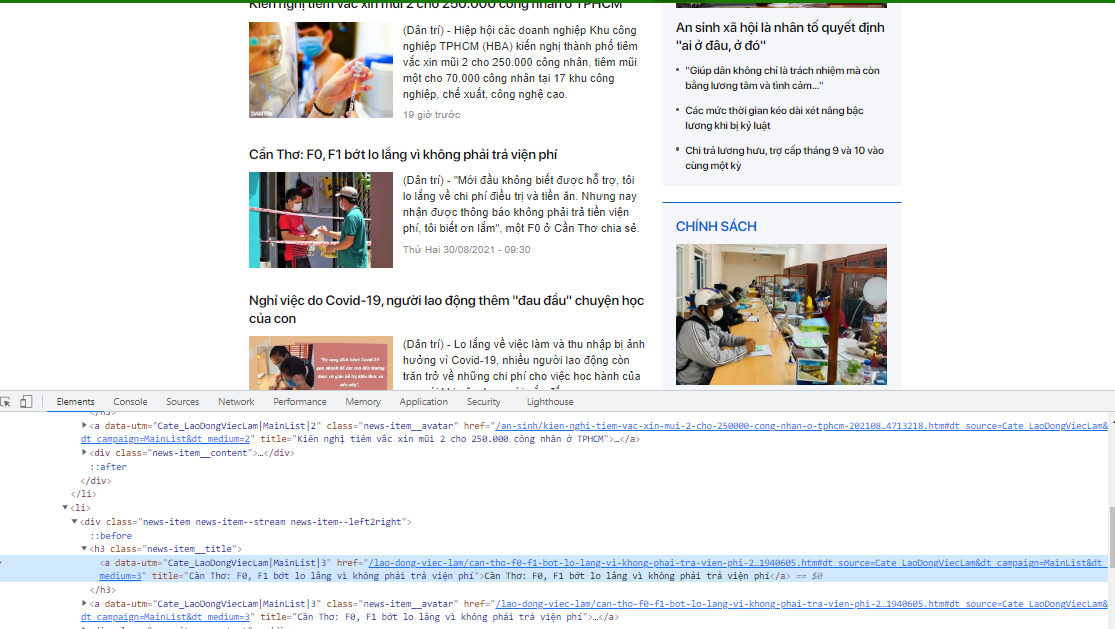
Như vậy ta đã lấy thành công thông tin bài viết, các bạn để ý rằng trong list bài viết ở cột trái hình đầu đều cấu trúc html như bài mình vừa cào, vậy để lấy được danh sách bài khác ta chỉ cần thay đổi link trong request. Làm thế nào để lấy được list link, ta làm tương tự phần cào dữ liệu ở trên, thứ mình cần lấy là link trong href của thẻ a ở page lúc đầu mình cần lấy .
public function handle()
{
$crawler = GoutteFacade::request('GET', 'https://dantri.com.vn/lao-dong-viec-lam.htm');
$linkPost = $crawler->filter('h3.news-item__title a')->each(function ($node) {
return $node->attr("href");
});
foreach ($linkPost as $link) {
print($link . "\n");
}
}
href mà mình cần lấy nằm trong thẻ h3 có class là news-item__title, mình sẽ chọc vào thẻ h3 lấy thẻ a và attr là href.
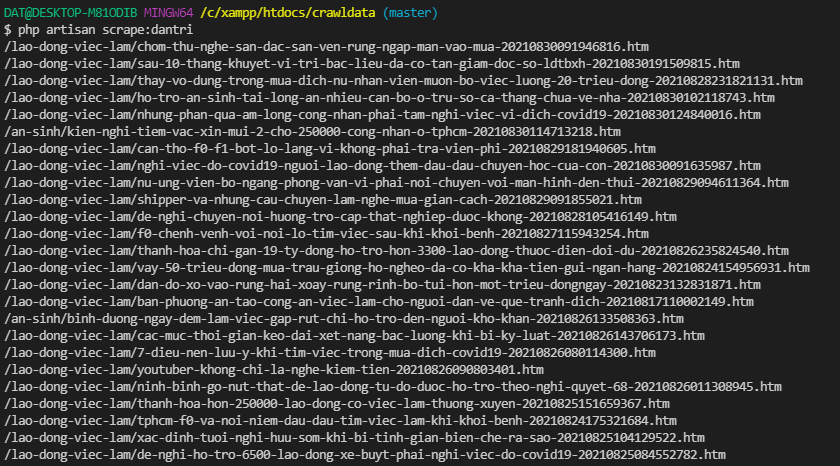
Mình đã lấy ra mảng linkPost chứa link những bài viết, vậy mình chỉ cần dùng vòng lặp chọc vào từng link một và xử lý bằng logic lúc ban đầu để lấy title, description, content là mình có thể lấy được được hết nội dung của đống bài viết này rồi.
/**
* Execute the console command.
*
* @return int
*/
public function handle()
{
$crawler = GoutteFacade::request('GET', 'https://dantri.com.vn/lao-dong-viec-lam.htm');
$linkPost = $crawler->filter('h3.news-item__title a')->each(function ($node) {
return $node->attr("href");
});
foreach ($linkPost as $link) {
self::scrapedata($link);
}
}
public static function scrapedata($url)
{
$crawler = GoutteFacade::request('GET', $url);
$title = $crawler->filter('h1.dt-news__title')->each(function ($node) {
return $node->text();
})[0];
$description = $crawler->filter('div.dt-news__sapo h2')->each(function ($node) {
return $node->text();
})[0];
$description = str_replace('Dân trí', '', $description);
$content = $crawler->filter('div.dt-news__content')->each(function ($node) {
return $node->text();
})[0];
$dataPost = [
'title' => $title,
'content' => $content,
'description' => $description
];
post::create($dataPost);
}
Mình đã chọc vào từng link và xử lý bằng hàm scrapedata, logic của scrapedata, handle thì tương tự nhau và mình cũng đã hướng dẫn từ đầu. Ở cuối mình có lưu vào database, phần này các bạn tự tạo model, table để lưu nhé. Và thành quả cuối cùng khi các bạn chạy $ php artisan scrape:dantri thành quả của các bạn sẽ được như thế này, các bạn có thể dùng data này test trên project của mình nhé.
Mình đã hướng dẫn các bạn lấy thông tin các bài viết của mục Việc Làm, và link trong handle() mình đang để cứng, vậy để lấy được nhiều mục khác hơn nữa, các bạn chỉ cần làm tương tự như handle với list link trên phần navbar.

Các bạn hãy thử test lấy thông tin sản phẩm bao gồm tên sản phẩm, giá sản phẩm... trên những web khác.
Lưu ý: các bạn sử dụng data với mục đích test hoặc nghiên cứu thôi nhé
![[Laravel] Tích hợp thông báo Line với Line Notify](/content/images/size/w720/2021/08/line-notify-678x381.jpg)